
Business Case:
The benefits of moving to the cloud-based infrastructure have been most noticeable in the speed at which products and services are now delivered, although productivity savings are also significant. Migration solutions with a high level of automation will minimize planned downtime—but avoiding manual operations is also an important factor in minimizing unplanned downtime and avoiding business disruption.
Cloud services offer Less Costs, 24 X 7 Availability, scalability, Elasticity, Security etc. technological advantages hence, AARP wants to build their solution in AWS and Databricks. Objective of this is to build DataLake for all input resource systems and Build Datamart for Business User analytics reporting part.
Key Challenges:
- Getting the input files from various system in different file formats
- Integrate AWS and Databrick. Need to up and down cluster during Databrciks spark job execution time only with Auto scaling
- Write each and every process (Input source to DataLake and, from DataLake to Datamart) as part of Spark job
- Need to setup Airflow as scheduling tool to run the Databricks spark jobs
Solution:
We developed processes and best practices that enable us to significantly get benefit out of Cloud implementation and reduce cloud expenditures for our clients. Additionally, we created reports to track resource status and utilization.
Environment: AWS, DataBricks, Spark
Key Highlights:
- Written Spark jobs to handle different file types
- Prepared DataLake lake in AWS S3 and Datamart in Redshift
- Written spark job to handle all business logic and for data purification / prepation before pass it to Datamart
- Used Open source Airflow tool for Spark job scheduling
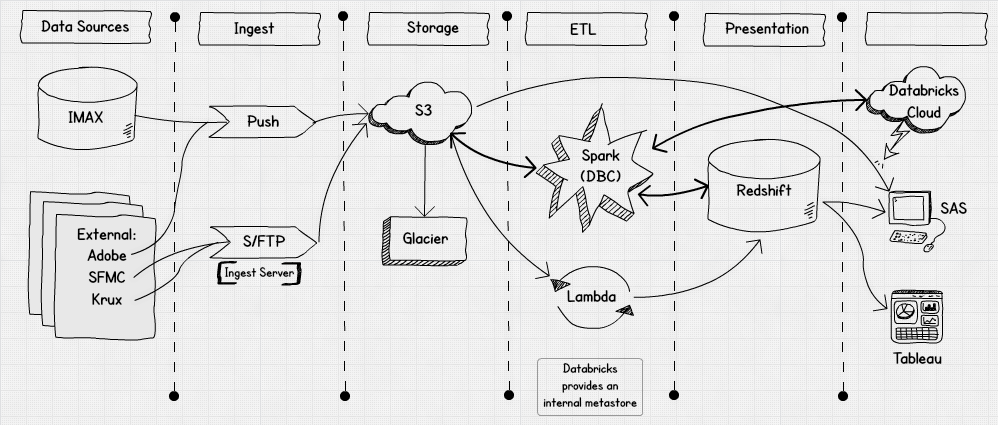
Data Lake Architecture
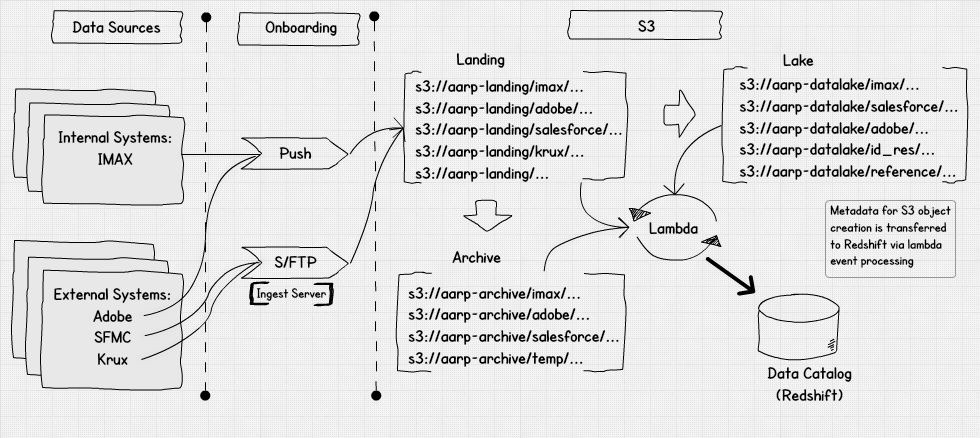
Ingest and Storage
Business Outcome:
- Each and every process has been automated from File ingest to DataLake and, from DataLake to Datamart using Airflow scheduling tool with Spark scheduled jobs
- By using, AWS cluster we have to reduce the cost of on premise resource as we are using Databricks cluster as and when we are running Spark jobs only, after that we are shutting down the cluster
- By using, AWS S3 and Redshift, we have saved lot of customer cost and provided more security to data, as it is part of AWS cloud
- By using, Airflow scheduling tool, customer job is easy to debug and trace Spark failed jobs