
What is Topic Modeling?
Topic modeling is a powerful unsupervised machine learning technique that has found applications in various domains, from social media analysis to healthcare and cybersecurity. It allows us to uncover latent thematic topics within a corpus of documents. While several traditional topic modeling methods like LDA, NMF, Top2Vec, they often overlook the context of words in a sentence, which limits their ability to generate coherent and diverse topics.
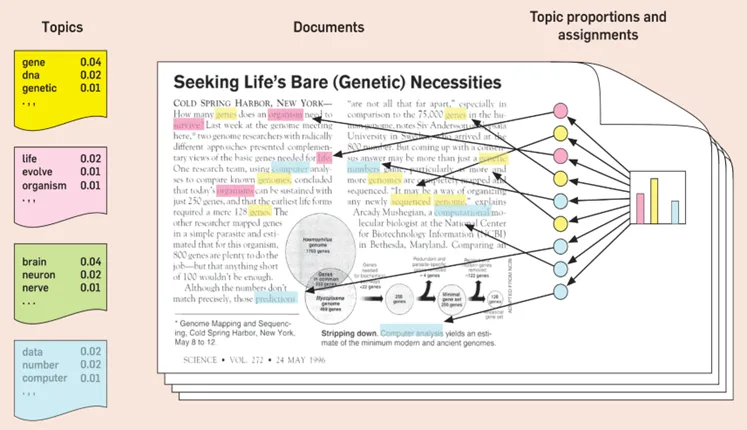
Figure source: Blei, D.M. (2010) Probabilistic topic models communications of the ACM, 55(4) 77–84
BERTopic
To overcome the issues of traditional methods, BERTopic was introduced. It is topic modeling technique that leverages clustering techniques and a class-based variation of TF-IDF to generate coherent topic representations.
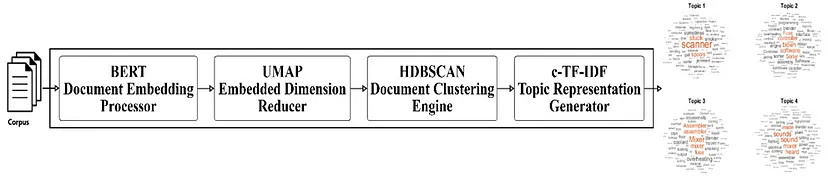
Base Framework of BERTopic
An Enhanced BERTopic Framework
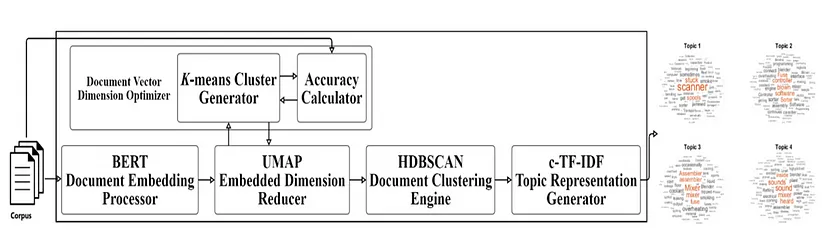
Advanced BERTopic Framework
In this figure, we present an improved version of the BERTopic framework, which includes a Document Vector Dimension Optimizer (DVDO). This enhancement allows for the dynamic optimization of the number of dimensions for each document vector, resulting in more optimal topics. Unlike the original framework, which used a constant dimension across all datasets for each document embedding method, our DVDO adapts to the characteristics of each dataset.
Key Components of the Enhanced BERTopic Framework:
- Document Vector Dimension Optimizer (DVDO): This pivotal addition to the BERTopic framework dynamically optimizes the number of dimensions for each document vector. By doing so, it tailors the dimensionality of document embeddings to the specific dataset, ensuring more effective topic generation.
- K-means Cluster Generator (KCG): Integrated into the framework, the KCG plays a vital role in optimizing document vector dimensions. It assists the DVDO in determining the ideal dimensions to capture the underlying document relationships.
- Sentence Transformers (SBERT): The foundation of document embeddings, SBERT models like “paraphrase-multilingual-MiniLM-L12-v2” are used to map sentences and paragraphs into dense vector spaces. The framework offers flexibility for users to choose alternative embedding models to suit their specific requirements, such as Google’s Universal Sentence Encoder, OpenAI GPT-2, or our Context-aware Embedding Model.
- UMAP Embedded Dimension Reducer (EDR): UMAP is employed to reduce the dimensions of document embeddings. By default, it reduces them to five dimensions, but users can adjust the dimensionality as needed. We utilize this flexibility of UMAP and provide the best and optimized dimensionality specific to the corpus used during training of the model.
- HDBSCAN Document Clustering Engine (DCE): The HDBSCAN module clusters semantically similar documents based on the reduced embedded vectors.
- c-TF-IDF Topic Representation Generator (TRG): This module generates topics by treating all documents within the same cluster as a single document. It employs a class-based TF-IDF (c-TF-IDF) computation to identify the most significant words or phrases within each cluster, enhancing topic quality and coherence.
By combining these components, the enhanced BERTopic framework with DVDO offers a more dynamic and adaptable approach to topic modeling. It ensures that document vector dimensions are optimized for each dataset, resulting in improved topic quality and relevance.
Conclusion
The enhanced BERTopic framework with the Document Vector Dimension Optimizer represents a significant advancement in topic modeling. It addresses the limitations of static dimensionality and provides a more adaptable and effective approach for generating coherent and diverse topics from textual data. Researchers and practitioners can benefit from this enhanced framework to extract valuable insights across various domains and datasets.
P.S: More details about this paper available here